Diabetes Prediction Project
A machine learning diagnostic tool built to address the demographic shift in Singapore, where 1 in 4 citizens will be 65 or older by 2030. This system predicts the likelihood of diabetes based on lifestyle and health indicators, facilitating early detection and providing actionable health recommendations for medical practitioners.
The Brief
Target Audience
Healthcare Providers, Clinical Researchers, Medical Diagnostic Labs, General Practitioners, and Health Policy Strategists.
My Role
-
Performing Exploratory Data Analysis (EDA) using Seaborn and Matplotlib to identify key risk factors like BMI and age trends.
-
Engineering a robust data pipeline involving outlier removal (IQR method) and categorical feature encoding (One-Hot Encoding).
-
Implementing SMOTE (Synthetic Minority Over-sampling Technique) to address significant class imbalance in the clinical dataset.
-
Training and comparing multiple classifiers including Random Forest, Logistic Regression, and Gradient Boosting using Scikit-Learn.
-
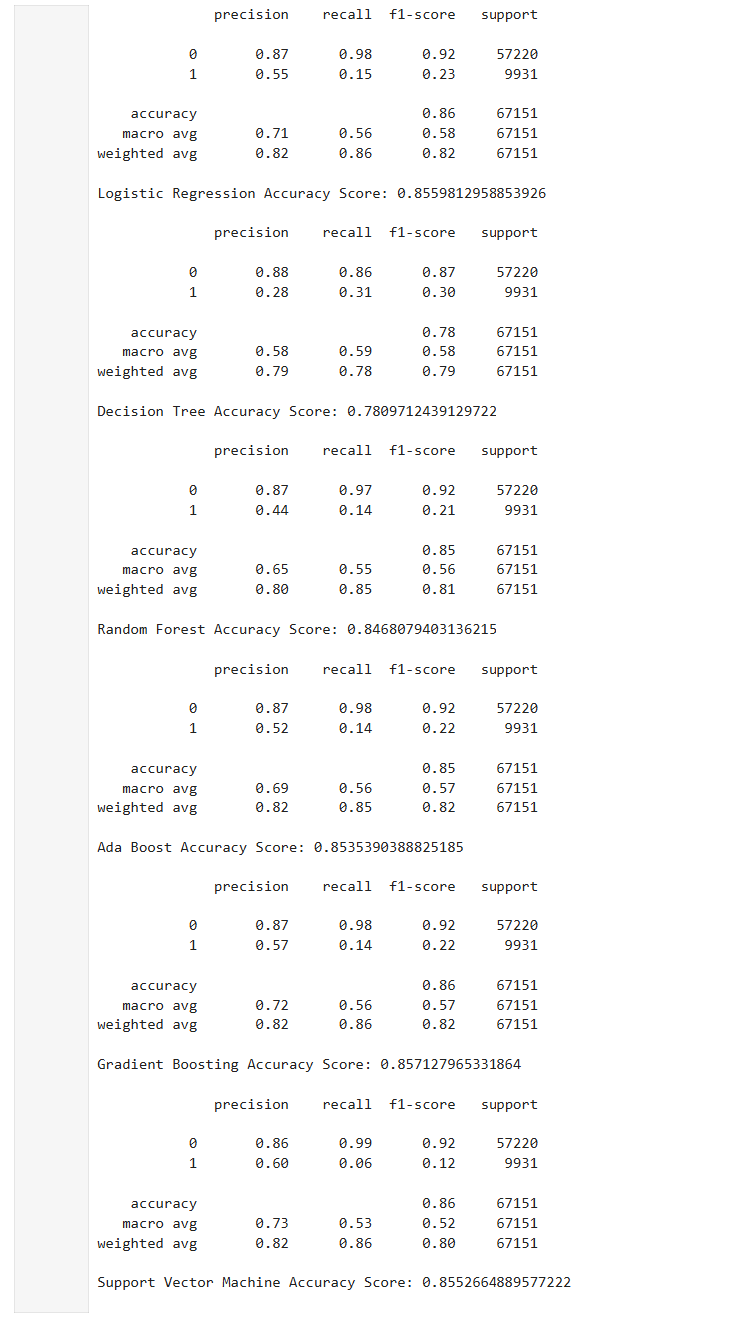
Selecting and justifying the AdaBoost model based on clinical business logic, prioritizing a 0.65 Recall rate over raw accuracy.
The Problem
The Solution
By 2030, the surge in chronic diseases like diabetes will significantly strain the healthcare system. Many standard AI models fail in this domain because they prioritize "Accuracy," which leads to missing sick patients (False Negatives). In a medical screening scenario, a False Negative is far more costly than a False Positive, as it delays life-saving intervention.
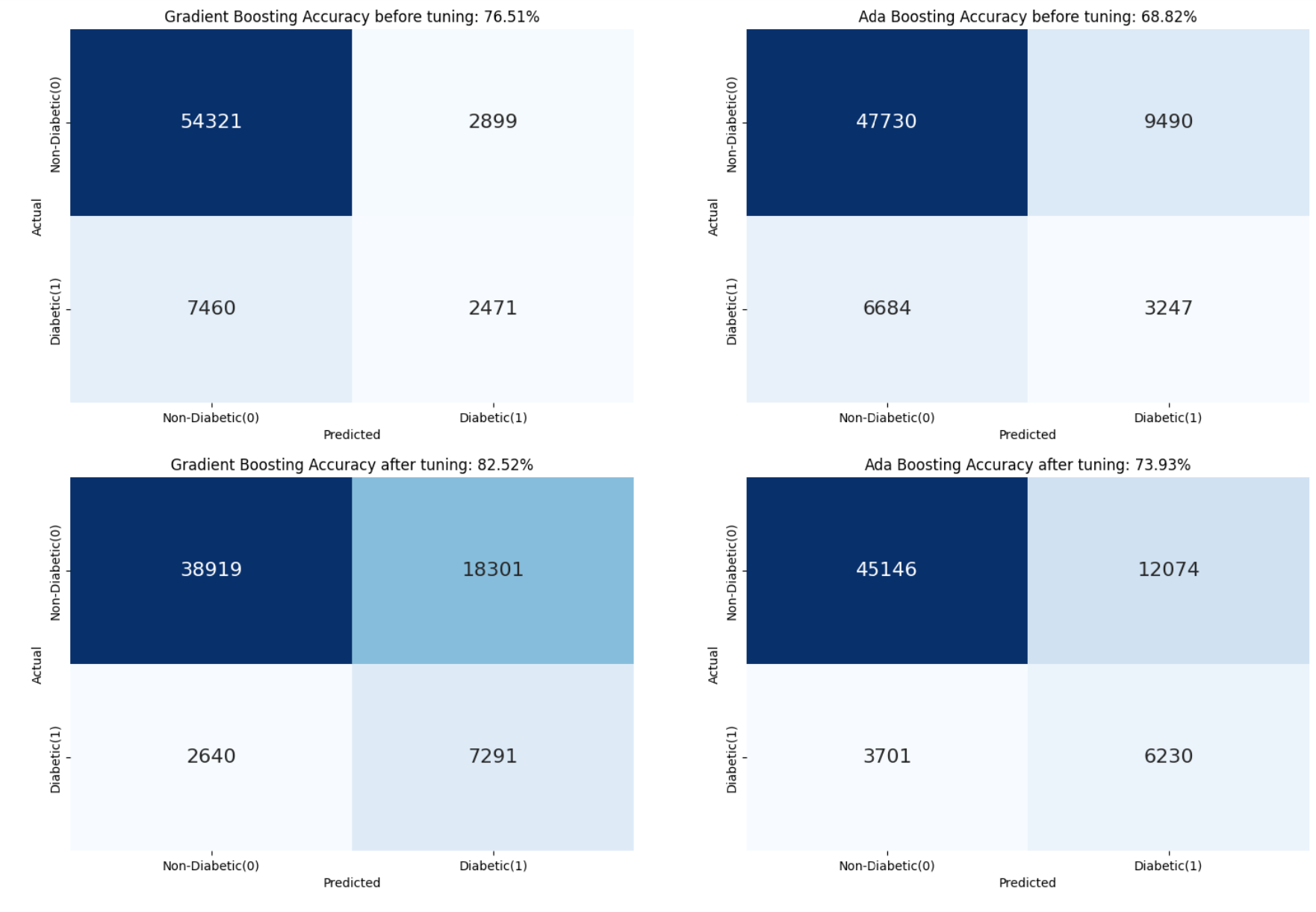
I developed a screening-focused pipeline that utilizes AdaBoost to maximize the detection of at-risk individuals. While other models like Gradient Boosting missed 71% of diabetic cases, my implementation reached a 0.65 Recall rate, identifying the majority of at-risk patients and providing a reliable tool for doctors to issue early health recommendations.
Process
-
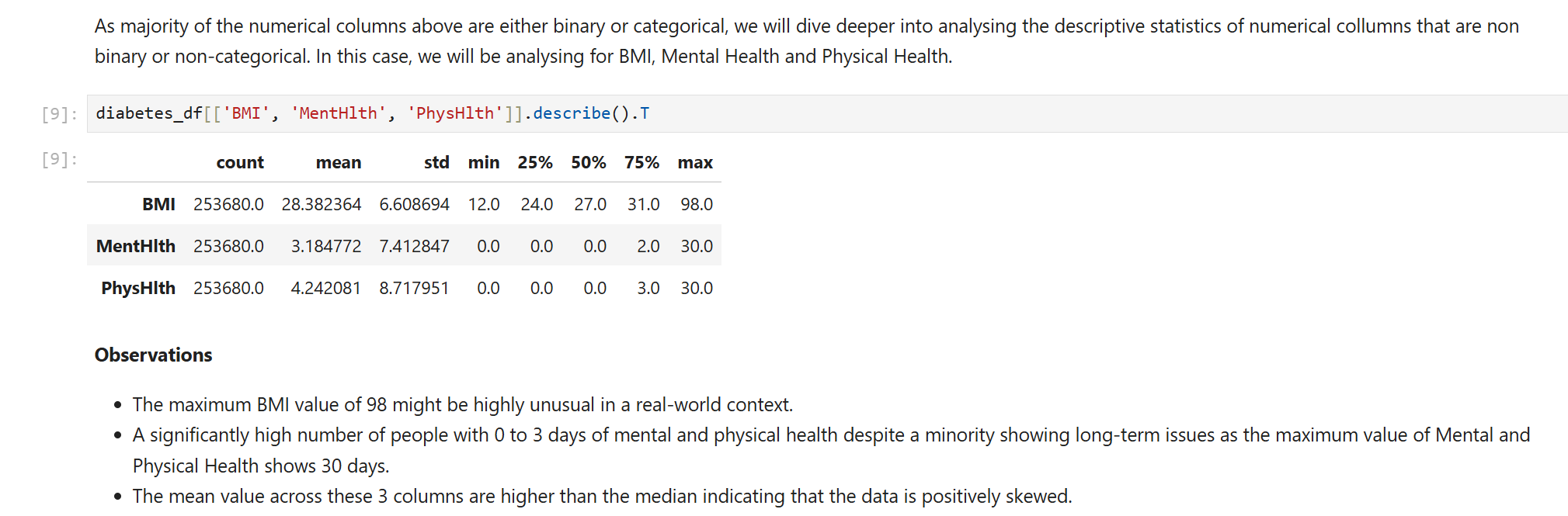
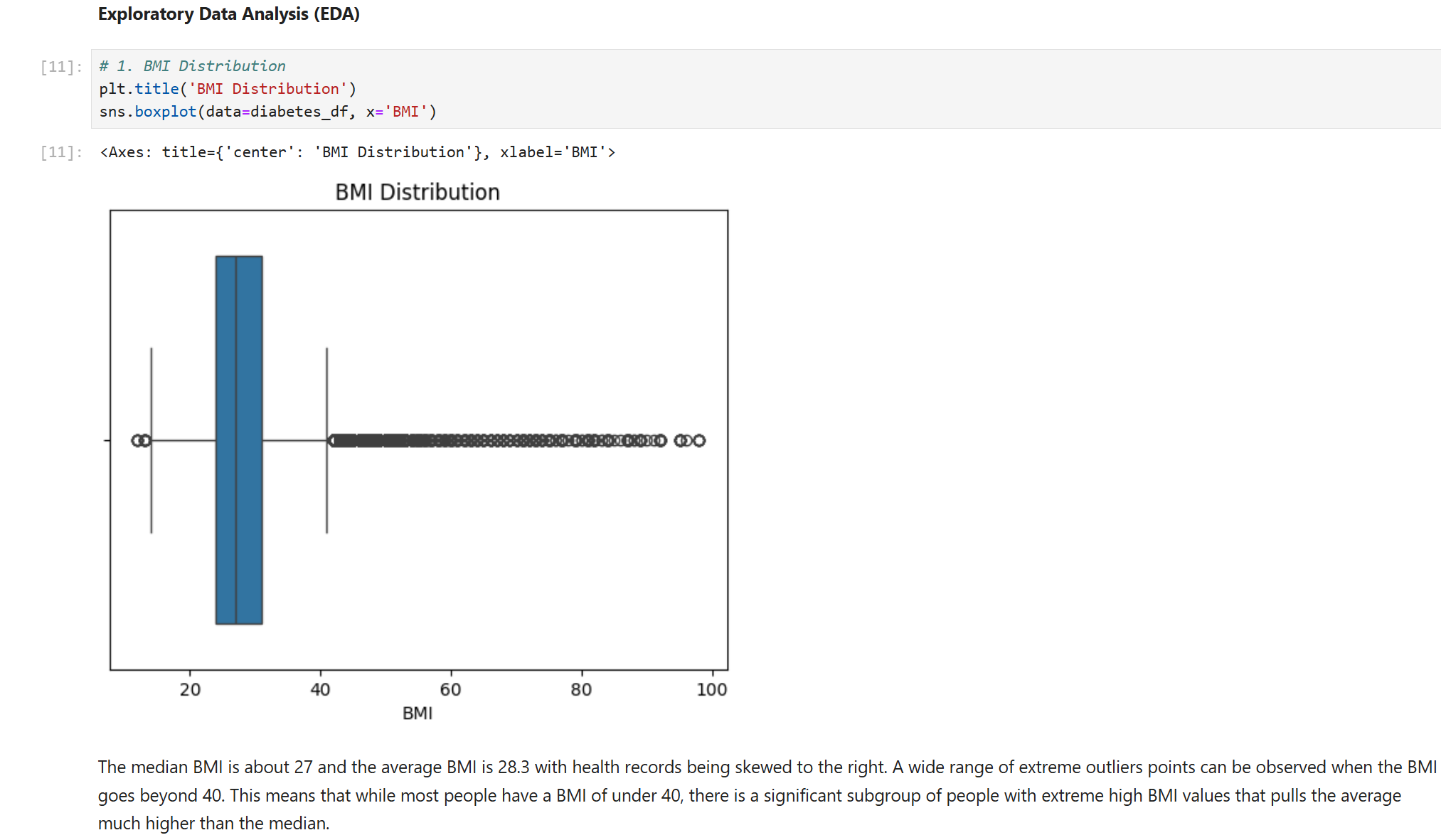
Clinical Data Audit: Analyzed health indicators (BMI, Physical Health, Mental Health) and addressed challenges such as high-BMI outliers (up to 98) and duplicate records.
-
Visualization & Insights: Used Seaborn to visualize how age and BMI significantly scale with diabetes risk, providing a data-driven foundation for the model.
-
Pipeline Engineering: Applied One-Hot Encoding to categorical features like "Education" and "Income" and scaled numerical data to ensure mathematical stability.
-
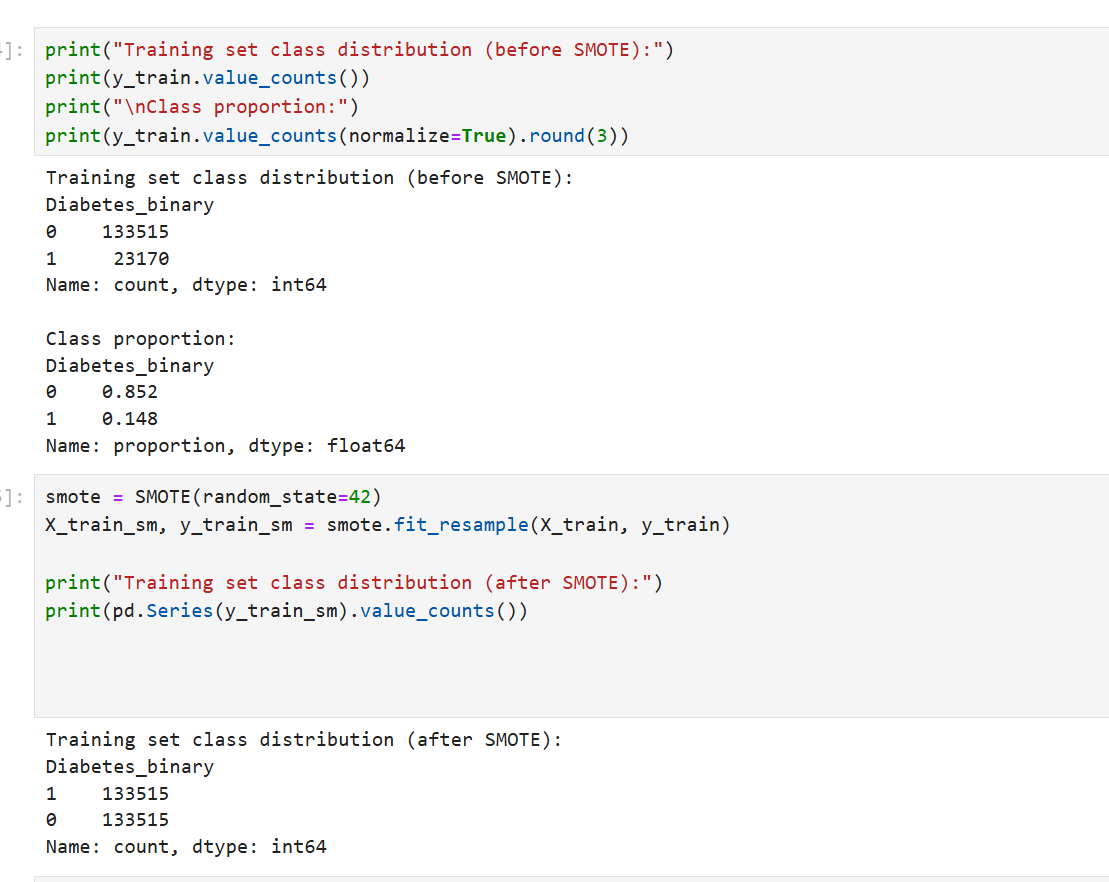
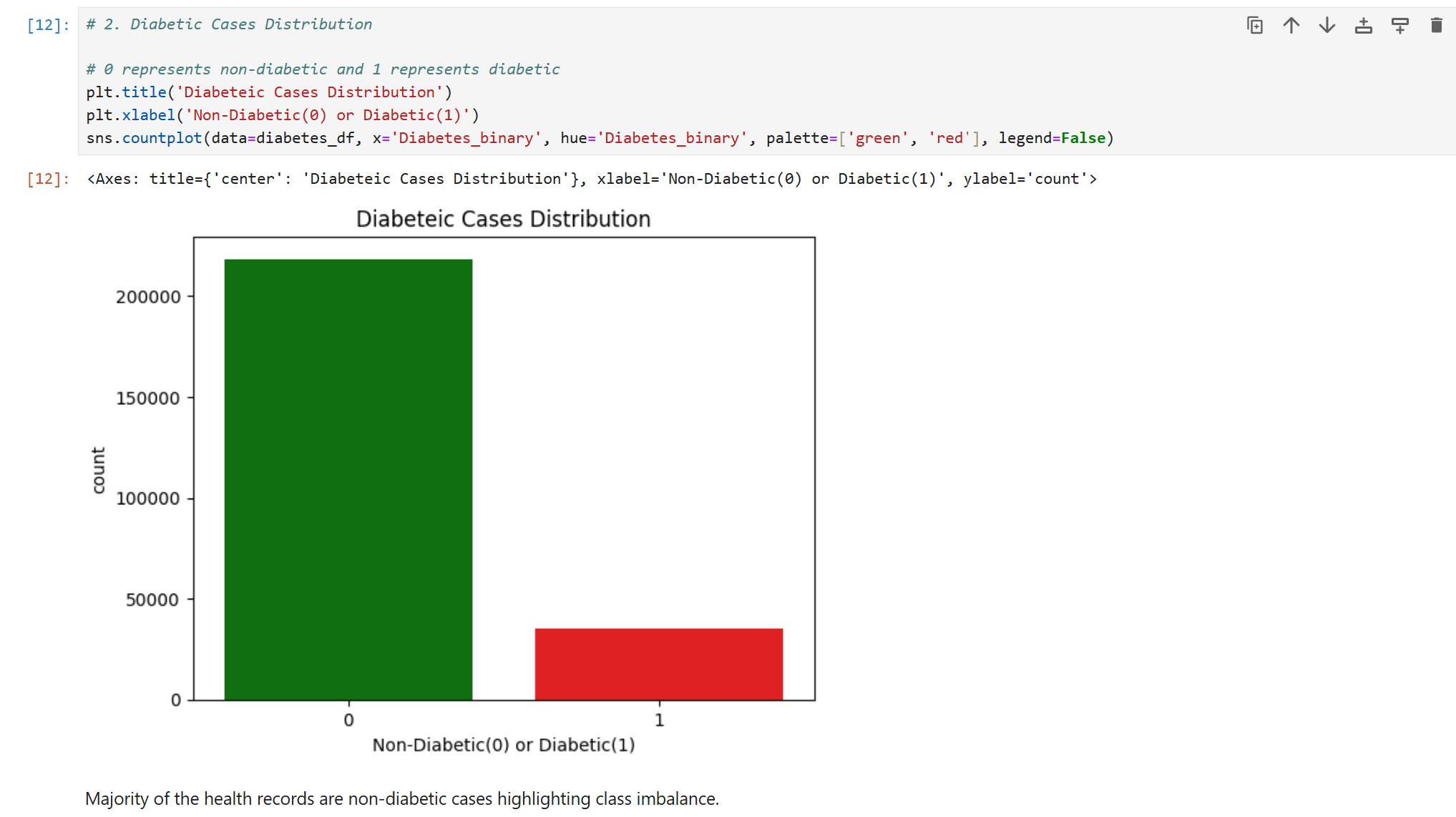
Handling Imbalance: Used SMOTE to address the 85:15 class imbalance, preventing the model from ignoring the diabetic population.
-
Model Selection Logic: Compared six classifiers (Logistic Regression, Decision Tree, Random Forest, AdaBoost, Gradient Boosting, Linear SVC). I selected AdaBoost because its superior recall ensures health practitioners can identify the maximum number of at-risk individuals.
Tech Stack
-
Language: Python
-
Machine Learning: Scikit-Learn (AdaBoost, Random Forest, Linear SVC)
-
Data Manipulation: Pandas, NumPy
-
Imbalance Handling: Imbalanced-Learn (SMOTE)
-
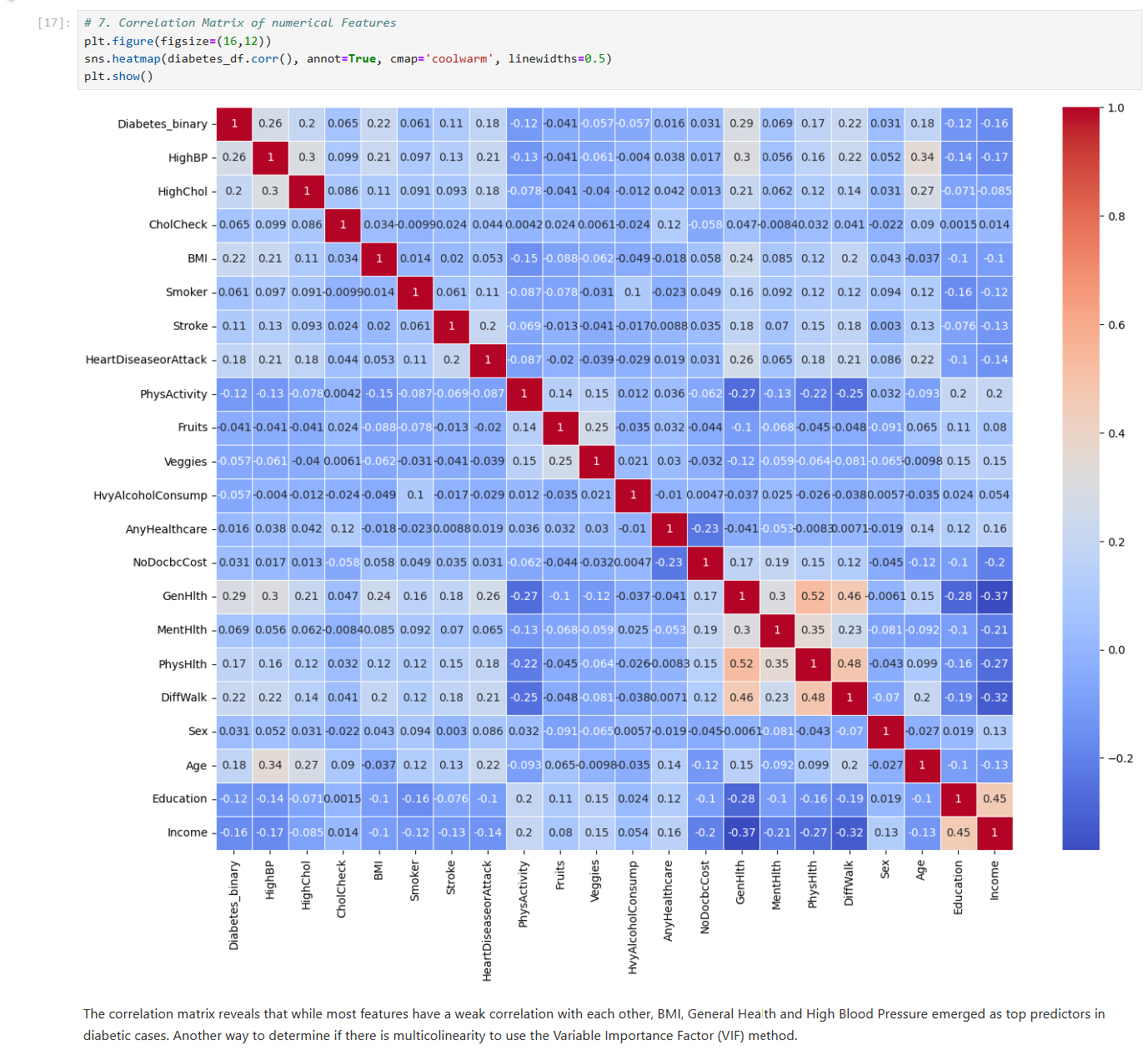
Visualization: Matplotlib, Seaborn (for risk distribution and correlation heatmaps)
Project Gallery








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Results
-
Optimized Screening Recall: Achieved a 0.65 Recall for diabetic cases, successfully identifying 65% of the at-risk population compared to only 29% in other models.
-
Clinical Viability: Reduced the rate of missed diagnoses by over half compared to standard boosting techniques.
-
Feature Intelligence: Identified BMI, General Health, and High Blood Pressure as the top three predictors for early intervention.
-
Business Impact: Successfully built a tool that aligns with Singapore's "Healthier SG" goals by focusing on early detection rather than just high accuracy.